
What is Kafka
Updated:
What is Kafka
1. Kafka 구조
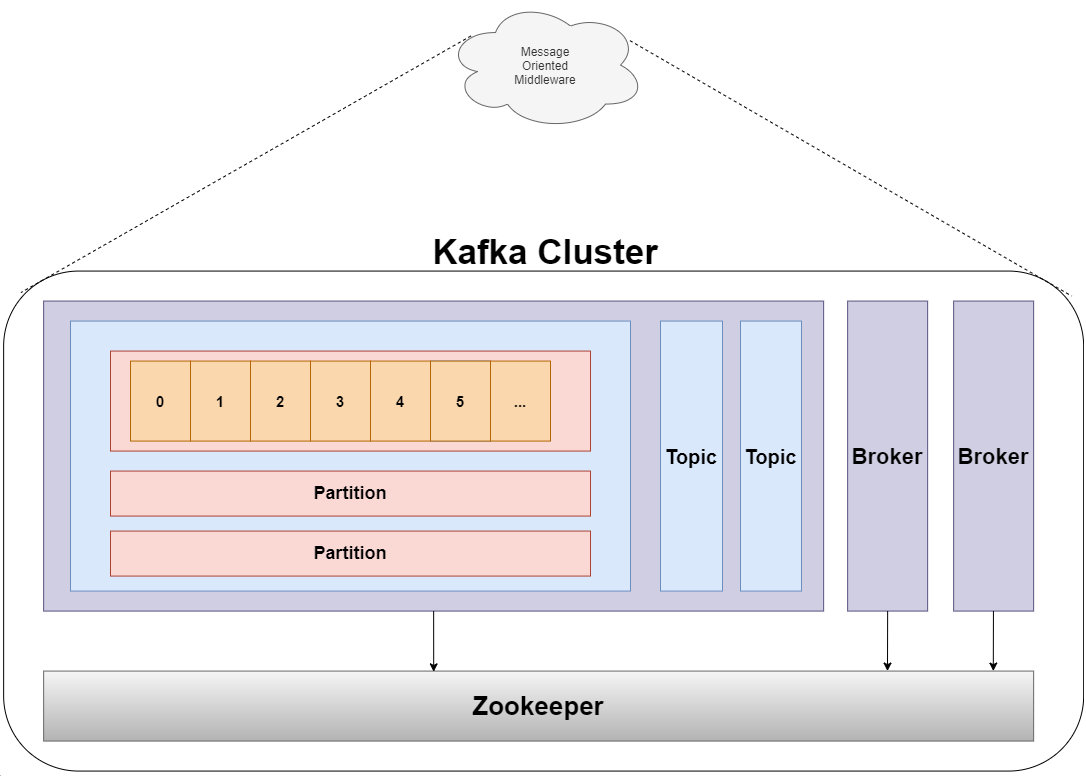
- Zookeeper ( Apache Zookeeper )
- 본래 Zookeeper의 용도는 클러스터 최신 설정정보 관리, 동기화, 리더 채택 등 클러스터의 서버들이 공유하는 데이터를 관리하기 위해 사용됨
- Kafka에서는 분산 처리된 메시지 큐의 정보들을 관리하는 목적으로 사용
- 클러스터를 관리하는 Zookeeper 없이는 Kafka 구동이 불가능
- Broker
- Kafka server를 의미 (Kafka server == broker)
- 한 클러스터 내에서 Kafka server를 여러 개 띄울 수 있음
- Topic
- 메시지가 생산되고 소비되는 주제
- 일반적으로 주제에 따라 Topic을 나누어 메시지를 관리
- 예를 들어, 카톡 단체방 A, B가 있는데, A 방으로 보낸 메시지가 B 방에 노출되면 안되므로, A 방에서 생산된 메시지는 A 방에 존재하는 사람들(구독한 사람)에게만 보여져야 함
- Partition
- Topic 내에서 메시지가 분산되어 저장되는 단위
- 한 Topic에 Partition이 3개 있다면, 3개의 Partition에 대해서 메시지가 분산되어 저장
- Queue 방식으로 저장되기 때문에 Partition의 끝에 저장이 되며, Partition 내에서는 순서를 보장해주지만, Partition끼리는 메시지 순서를 보장해주지 않음!
- 그래서 Topic 내에 하나의 Partition이 존재할 때에는 메시지 Consume시 순서를 보장해주지만, 여러 개의 Partition이 존재할 때는 순서를 보장할 수가 없음
- Log
- Partition의 한 칸을 Log라 칭함
- Log는 key, value, timestamp로 구성됨
- Offset
- Partition의 각 메시지를 식별할 수 있는 unique한 값
- 메시지를 소비하는 Consumer가 읽을 차례를 의미하므로 Partition마다 별도로 관리
- 0부터 시작하여 1씩 증가하는 방식
2. Producer and Consumer Group
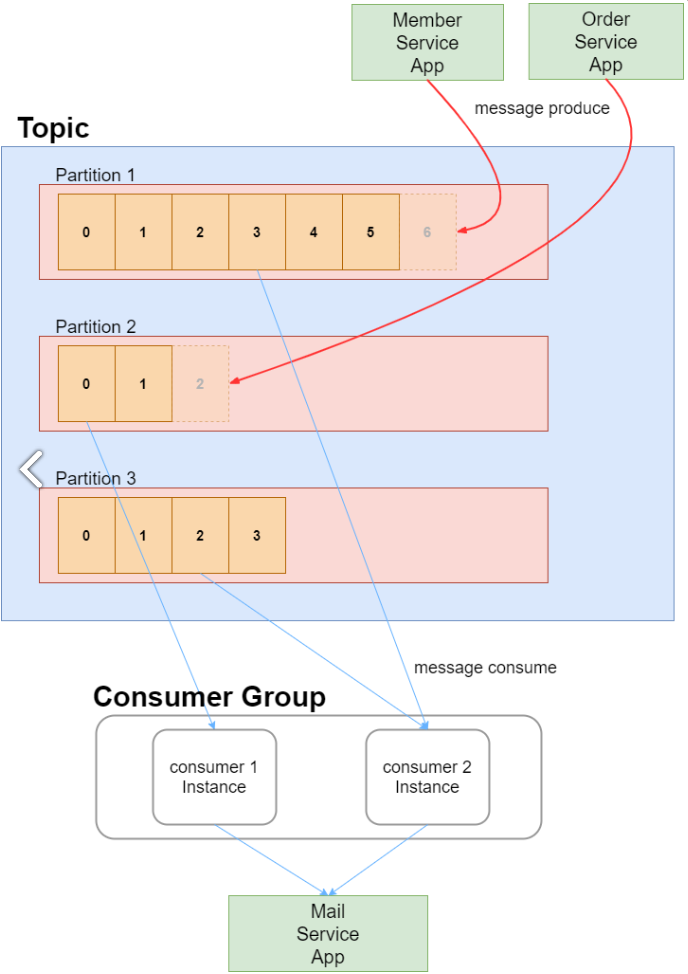
- Producer
- Producer는 정해진 Topic에 메시지를 기록하는 주체
- Topic에 Partition이 여러 개 있을 경우, 기록 될 Partition의 선택은 기본적으로 Round-Robin 방식을 따름
- Partition이 여러 개 있으면 병렬 처리라는 이점이 있지만, Partition 개수는 주의해서 잘 설정해줘야 합니다.
- 각 Partition 내에서는 가장 마지막 offset 뒤에 신규 메시지가 저장되므로, Partition 내에서는 순서가 보장되며 기록이 됨
- Consumer Group
- Consumer Group은 하나의 Topic을 담당
- 즉, Topic은 여러 개의 Consumer Group이 접근할 수 있지만, 하나의 Consumer Group은 하나의 Topic에만 접근이 가능
- 존재 의의 1 : Partition 접근하는 Consumer 관리
- Consumer Group 내에 있는 Consumer 인스턴스들은 Topic내에 Partition에서 다음에 소비할 offset이 어디인지 공유하면서 메시지를 소비하기 때문에, 다음에 소비할 offset을 잘 관리할 수 있음
- 만약 Consumer Group이 없을 경우, 하나의 Partition에 2개의 Consumer가 동시에 접근한다면 어떤 Consumer가 몇 번의 offset을 소비해야 하는지 알 수 없게 되는 문제가 발생
- 존재 의의 2 : Offset 공유를 통한 고가용성 확보
- Partition에는 하나의 Consumer 인스턴스만 접근할 수 있기 때문에, 특정 Consumer 인스턴스에 에러가 발생했을 시 다른 Consumer 인스턴스는 에러가 발생한 Consumer 인스턴스가 소비하던 Partition을 소비하게 됨
- 즉, Consumer가 다운될 때를 대비해 Consumer Group의 Consumer 인스턴스들은 offset을 공유하고 있으며, 이를 통해 고가용성 확보
- Consumer Group 이해를 위한 좋은 글 : https://www.popit.kr/kafka-consumer-group
- 결과적으론, Partition의 개수 >= Consumer 인스턴스의 갯수를 유지하는 것이 좋음
3. RabbitMQ vs Kafka 비교
- RabbitMQ
- Message Broker가 Consumer에게 메시지를 push 하는 방식
- Broker는 Consumer의 처리여부에 관계없이 push를 하므로, 메시지 소비 속도보다 생산 속도가 빠를 경우 Consumer에 부하를 주게됨
- RabbitMQ는 DRAM을 사용하므로 buffer를 사용하지만, DRAM을 다 사용하면 disk에 저장합니다. 따라서 batch 같이 큰 작업에서는 disk로 메시지를 읽어올 경우 지연이 발생
- Kafka
- Consumer가 Broker로부터 메시지를 pull 하는 방식
- Consumer가 처리할 수 있을 때 메시지를 가져오므로 자원을 효율적으로 사용
- Kafka는 애초에 메시지를 disk에 저장하고, 이미 처리한 과거의 offset으로 자유롭게 움직일 수 있으므로 batch 작업에서 자원의 낭비라던지 지연이 발생하지 않음
- 메시지를 쌓아두었다가 처리하는 batch Consumer 구현도 가능
- 데이터가 없음에도 정기적인 polling으로 인해 자원을 낭비하는 문제가 발생할 수 있어서, 이러한 단점을 보완하기 위해 실제 데이터가 도착할 때까지 long poll 대기를 할 수 있는 parameter를 지원
- 관련 공식 문서 : https://kafka.apache.org/documentation/#design_pull
4. Replication
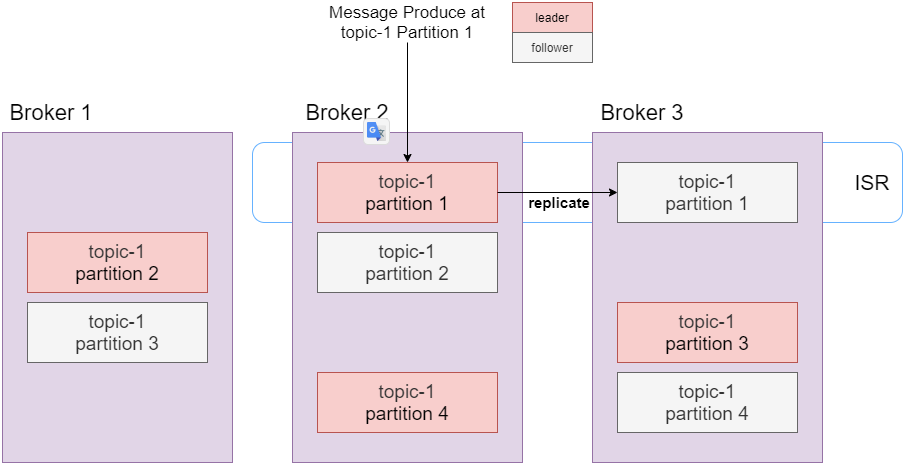
- Replication이란 Zookeeper가 leader가 되는 Partition을 정하고, Partition을 각 broker마다 복제를 하는 것을 말함 (leader를 복제하는 partition을 follower)
- leader : 메시지를 생산하고 소비하는 작업은 모두 leader broker에서 이뤄짐
- follower : 나머지 follower들은 leader를 복제만 함
- Topic을 생성할 때, –replication-factor 옵션을 부여하면 복제본(replication)을 생성
Leave a comment